DFS = 깊이 우선 탐색
노드와 간선이 주어지는 그래프에서 방문하지 않은 노드를 방문가능한 노드가 없는 노드에 도달할 때 까지 방문한다.
- 현재 노드와 연결된 노드 중 아직 방문 안한 노드가 있으면 그 노드로 간다
- 방문할 노드가 없으면 다시 이전 노드로 돌아감
- 이를 모든 노드 방문 완료할때까지 반복한다!

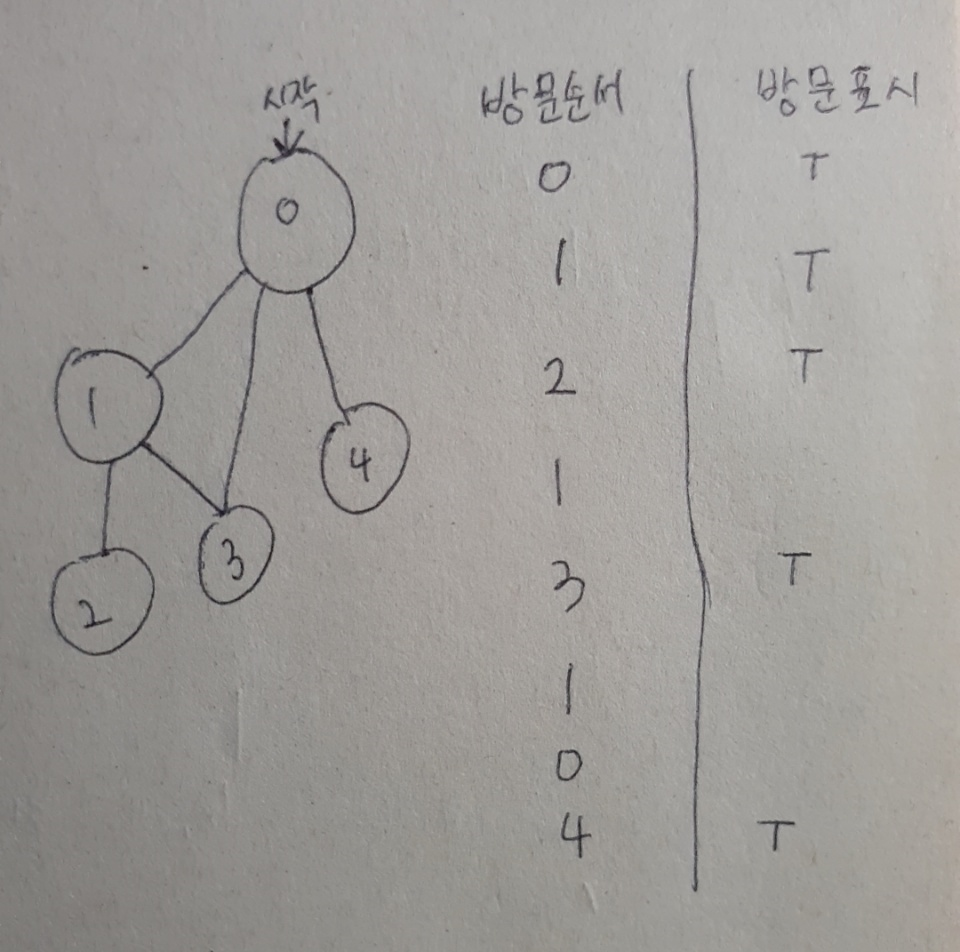
DFS구현 방법
1) 입력 받기
노드와 간선 입력받기
-어떤 노드와 어떤 노드가 연결되었는지를 알아내기 위해 노드 갯수만큼의 크기를 가진 배열을 선언하고
배열의 인덱스 = 노드로 취급하여 연결된 간선 정보를 append한다
2) 1에서 입력받은 노드와 간선 정보를 바탕으로 깊이 우선 탐색을 수행
깊이 우선 탐색에는 두가지 방법이 있다.
[1] 스택
- while문 사용, 스택이 빌 때 까지
- 현재 방문 할 노드를 pop하여 방문 표시 한다
- 현재 노드에서 방문 가능한 노드(연결된 노드 중 방문하지 않은 노드)를 push한다
[2] 재귀함수
- 다음으로 방문 할 노드를 매개변수로 하여 재귀를 수행한다
* 파이썬에서 재귀함수는 스택보다 느리다
관련 문제 풀어보기
# 백준 24479 알고리즘 수업 - 깊이 우선 탐색 1
첫째 줄에 정점의 수 N (5 ≤ N ≤ 100,000), 간선의 수 M (1 ≤ M ≤ 200,000), 시작 정점 R (1 ≤ R ≤ N)이 주어진다.
다음 M개 줄에 간선 정보 u v가 주어지며 정점 u와 정점 v의 가중치 1인 양방향 간선을 나타낸다. (1 ≤ u < v ≤ N, u ≠ v) 모든 간선의 (u, v) 쌍의 값은 서로 다르다.
첫째 줄부터 N개의 줄에 정수를 한 개씩 출력한다.
i번째 줄에는 정점 i의 방문 순서를 출력한다. 시작 정점의 방문 순서는 1이다. 시작 정점에서 방문할 수 없는 경우 0을 출력한다.
import sys
node,line,first = map(int, sys.stdin.readline().split()) # sys.stdin.readline = input()보다 더 효율적인 입력
arr = [[]for _ in range(node+1)] # 파이썬 이중배열 선언 [[]]
result = [0 for i in range(node+1)] # 결과를 담을 배열
visited = [False for _ in range(node+1)] # 방문한 노드를 표시하는 배열
for i in range(line): # 간선 정보를 배열에 입력
a,b = map(int, sys.stdin.readline().split())
arr[a].append(b) # 방향이 없는 그래프이므로 두곳에 모두 입력
arr[b].append(a)
for i in range(len(arr)):
arr[i].sort(reverse=-1) # 스택 후입선출이라 정렬 reverse함. 재귀 방법일 땐 arr[i].sort()
# 재귀를 이용한 방법
# def dfs(r):
# visited[r] = True # 방문표시
# global count # 방문 순서 * 파이썬에서 전역 명령어 = global
# count +=1
# result[r] =count
# for i in arr[r]:
# if(visited[i]==False): # 방문 가능한 노드가 있을 때 다시 함수 호출
# dfs(i)
def dfs(r):
stack = []
stack.append(first) # 방문 할 노드 push
count = 0
while(stack):
curr = stack.pop()
if visited[curr] == True: # 이미 방문했다면 건너뛰기
continue
count += 1
result[curr] = count # 방문 순서
visited[curr] = True # 방문 표시
for i in arr[curr]: # 방문 가능한 노드가 있으면 스택에 넣기
if visited[i] == False:
stack.append(i)
dfs(first) # dfs수행
for i in result[1:]: # 출력
print(i)